
核心逻辑
智能体时代来临,小型端侧设备无法消化大模型大参数,而具身智能则有望成为最佳载体。从具身智能训练层面看,仿真软件可为大模型提供海量、低成本数据,解决真实数据高成本、难收集的问题,仿真软件有望实现大范围应用。相比于刚性物体的仿真,柔性、流体的仿真技术壁垒更高,具备相关技术积累的厂商优势突出。
从具身智能商业化路径来看,建议关注纯软件和垂直领域软硬一体路径。目前具身智能商业化路径主要包括三种:第一种是通用机器人路径,其核心是采用通用的硬件和软件来应对各种多变的使用场景,该种路径对于资金和技术要求较高,目前 1X、Figure 以及特斯拉等行业巨头正加速布局。第二种纯软件路径的是设计通用的操作系统,硬件厂商通过 API 接口即可接入机器人“大脑”,从而实现多种硬件平台共享同一套软件架构。并且随着机器人的大规模部署,其边际成本可以无限趋近于 0。对于纯软件路径,关注英伟达、华为合作厂商。第三种路径是垂直领域软硬一体,目前机器人硬件与数据仍处于耦合阶段,公司通过收集传感器数据能够形成细分领域的数据壁垒。
具身智能体
具身智能由本体和智能体组成。具身智能是一种基于物理身体进行感知和行动的智能系统,其通过智能体与环境的交互获取信息、理解问题、做出决策并实现行动。具身智能的核心要素包括本体和智能体。本体作为实际的执行者,在物理或虚拟世界负责感知和执行任务,而智能体则是具身于本体之上的智能核心,负责感知、理解、决策、控制等核心工作。区别于机器人,具身智能具备自我决策能力。根据卢策吾教授在机器之心 AI 科技年会上发表的《具身智能是通往 AGI 值得探索的方向》中提到,智能体通过感知器和执行器与环境进行交互后,能够实现获取信息、理解问题等功能,并根据环境的变化做出相应的决策和行动。
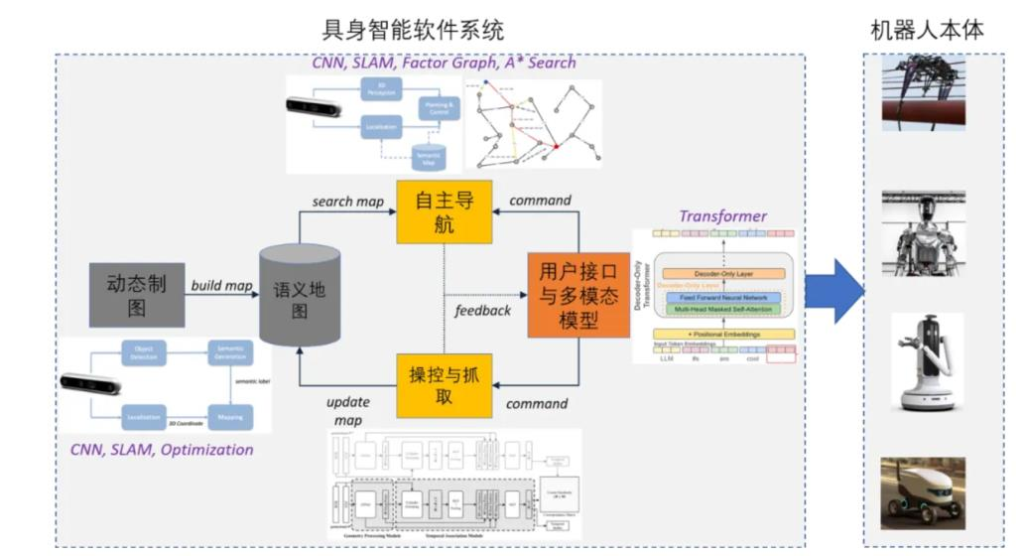
智能体使机器人由被动编程控制走向主动决策
由专机专用走向通用智能,大模型有望实现机器人系统的重构。2010 年以前,机器人更接近于专机型的自动化和智能化设备,以特定的机械结构解决针对性场景的作业问题,适用于相对单一、固定的结构化场景,泛化和迁移能力有限。并且由于机器人缺乏对于任务目标的深入理解,工程师需要进行大量的任务分解和编程工作,机器人的控制高度依赖人工编程。而且当任务对象或环境发生任意变化时,需要工程师重新对机器人进行编程和部署。
2010-2022 年间,机器人开始拥有初步的感知和规划能力,并逐步实现智能化。这一阶段,机器人在以下几个方面实现了单点突破:SLAM 技术与激光雷达结合产生了自主移动能力的 AGV(自动引导车)和 AMR(自主移动机器人);2012 年全球首家轻量级协作机械臂优傲(Universal Robots)进入中国市场,协作机械臂开始兴起;结合 AI 与 3D 视觉技术后,机器人能够自动进行物体识别和定位,规划最优路径,实现了上下料、拆码垛、无序分拣、焊接等非标自动化场景的人工替代。
2022 年后,大模型逐步与机器人结合。不同于上个阶段的单点性驱动,大模型所展现的泛化能力有望对机器人感知、决策、控制的整体系统能力带来全面重构,实现机器人的通用化。
与智能体结合后,具身智能以任务目标为导向,不仅仅是机械地完成程序,其可以根据环境变化,对行动细节进行实时修正,并消除在特定条件下为特定任务反复编程的需要。依托大模型的涌现能力,具身智能能够从原始训练数据中学习并发现新的特征和模式,在仅仅依靠网络数据知识的情况下就可以对从未见过的对象或场景执行操作任务。以微软《ChatGPT for Robotics: Design Principles and Model Abilities》为例,操控者只需准备好机器人底层的函数库,并将任务目标告诉 ChatGPT,ChatGPT 即可自动完成代码并指挥具身智能机器人行动。
智能体可实现机器人底层控制
智能体对机器人进行控制主要分为两种路径,一种是分层决策模型、二是端到端的具身模型。
分层框架的核心是将复杂的长时程任务拆解成可以直接完成的小任务。与机器人结合的大模型可分为两类: Foundation Models for Robotics 和 Robotics Foundation Models。 前者可与机器人结合但其应用领域并不局限于机器人,其主要功能是作为“大脑”对机器人进行任务分解和规划。后者是结合机器人数据训练生成到小脑层的基础模型,即机器人具身大模型,其作用是结合各种传感器的信息以及宏观指令进行运动指令生成。
以擦桌子为例:机器人接到任务后,首先将其拆解成一系列的子任务,即找到抹布、拿起抹布、擦桌子……传统的任务规划通常由工程师来进行,而大模型由于具备高层次抽象能力,可直接实现机器人的任务定义、拆解,使其实现自主任务规划。任务分解完成后,需要对机器人进行动作轨迹规划,例如从 A 点到 B 点进行 10 次圆周运动。传统控制通过直接驱动或电机控制来实现基础动作控制,需要工程师进行编程,而神经网络可以直接使用机器人编程语言完成应用程序的编写、调优和部署。
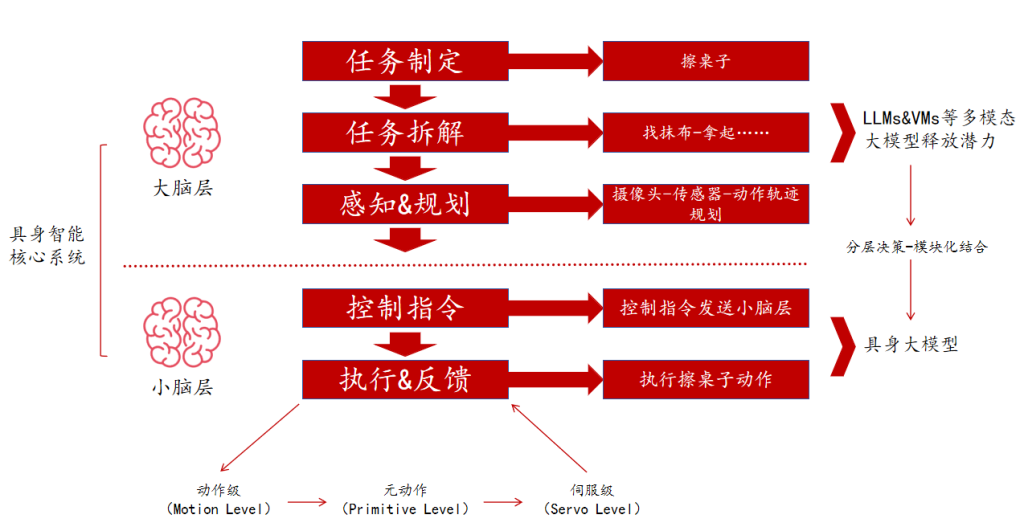
区别于分层架构,端到端大模型能够直接输出控制信号。以谷歌的 RT-2 为例,RT-2 是视觉-语言-动作(VLA)模型,能够从网络和机器人数据中进行学习,并将这些知识直接转化为机器人控制的通用指令。RT-2 以视觉-语言模型(VLMs)为基础,VLMs 在 web-scale 数据上进行预训练,能够准确识别视觉或语言模式并跨不同语言进行操作。在此基础上,谷歌将动作表示为类似于语言标记的标注,以实现在机器人数据上训练 VLM 模型。RT-2 能够理解复杂的指令并将其转化为机器人的动作,其接收机器人摄像头图像作为输入,直接预测机器人要执行的动作,实现了从视觉到动作的端到端控制。
端到端的架构具备更好的泛化性,分层架构可解释性更强。RT-2 能够处理机器人数据中从未见过的对象或场景,例如执行“拿起即将从桌子上掉下来的袋子”或“将香蕉移动到 2 加 1 的和”等。但端到端需要构建海量数据训练,且消耗大量计算资源。数据规模越大,调用大模型频率就越高,机器人决策实时性效果越差。分层架构可将复杂的问题分解为更小、更易于管理的部分,相比端到端技术难度更低,并且系统拥有更好的可扩展性和可维护性。但是其信息在不同层级之间传递时有可能会存在损失,因此会影响系统的整体性能和响应速度。
参考自动驾驶发展路径,在早期机器人数据不足的情况下,分层架构发展更为迅速。自动驾驶属于具身智能子集,是具身智能移动能力的体现。在自动驾驶初期发展阶段,分模块快速发展,在这种技术范式下,感知、决策、控制由开发人员各自完成,具备更强可解释性。而端到端虽然以全局最优为导向,相比传统分模块的方式具备更高性能上限,但实现难度较高,且需要海量数据做支撑。
数据是具身智能发展的核心
小模型时代算法的数量和质量对于机器人至关重要;然而大模型的 Scaling Law 表明通过增加数据量、扩大模型规模以及延长训练时间,可以实现模型性能的持续提升,数据重要性凸显。并且不同于语言、图像或视频等二维模型的训练,具身智能底层模型的训练,需要在物理世界绝对坐标系下的精确测量数据,数据获取难度、成本、标注周期都远超语言模型。从产业发展进程看,类比自动驾驶,特斯拉大规模采集的数据推动了 FSD 性能的提升,具身智能产业发展的核心在于数据。
类比自动驾驶,数据驱动产业发展。在产业发展初期,自动驾驶系统由规则驱动,即通过工程师人工编写规则代码使汽车对不同行驶状况作出决策。随着神经网络智驾算法的崛起,自动驾驶进入数据驱动时代。以特斯拉 FSD 为例,V12 版本 C++代码量仅为 2000 行,相比 V11 代码减少了 99%以上,其原理是通过大量数据训练出能够高度模拟人类驾驶习惯的人工智能,在达到一定的仿真阈值后,得出一套根据可靠性和符合人类乘车习惯的系统。特斯拉通过影子模式进行数据收集,将系统决策与驾驶员行为不断进行比对,当两者不一致时,系统将场景判定为“极端工况”,进而触发数据回传。因此特斯拉收集的数据越多,对于人类驾驶习惯的模拟就越精准,进而加速特斯拉车端的部署,形成数据闭环
具身智能获取数据的关键在于实现商业化落地。
区别于大模型可以从网络中获取数据并进行训练,具身智能如果想要具备高泛化性和可靠性,则需要在真实物理世界里获取数据来完善模型,而获取真实物理世界的数据的关键就在于商业化落地。根据 1X AI 副总裁 Eric Jang 在个人博客网站上发表的“All Roads Lead to Robotics”一文,具身智能的商业化路径主要包括三种:通用场景软硬结合、软件路径、以及垂直领域软硬结合。
垂直领域软硬结合能够积累细分数据壁垒。高工机器人产业研究所(GGII)所长卢瀚宸在 2024 中国人形机器人技术应用峰会上表示,具备高壁垒的核心硬件长期来看将是“香饽饽”。机器人领域硬件与数据强绑定,例如通过定制化的处理器或通信接口,公司能够收集和处理特定类型的数据,这些数据对于机器人的性能至关重要,但难以被竞争对手复制。同时,硬件和软件紧密集成形成高度优化的系统,这种集成化设计可以提高数据的收集效率和处理速度,从而形成数据壁垒。
软硬协同,海康机器人具备从机器人本体到业务调度系统的全面产品覆盖。公司在硬件方面具备机器人设计、无线通讯及自动充换电技术,在软件方面具备嵌入式技术、平台软件技术以及移动机器人定位导航、运动控制、调度规划等通用智能技术。公司机器人产品矩阵包括:移动机器人本体、自动充换电系统、通讯系统、机器人调度系统和业务系统。其中移动机器人本体是硬件核心,具备定位、导航和一定的自主决策能力;通讯系统主要负责机器人群体和机器人调度系统之间的无线通讯,一般以 WIFI 或 5G 讯号进行链接;充换电系统主要负责给机器人补充电能;机器人调度系统既是软件的核心也是整个系统的核心,主要负责将工厂的作业任务分配给合适的机器人,并负责整个机器人群体的交通调度;业务系统负责将工厂的需求指令转换为机器人的搬运指令,并下发给机器人调度系统。
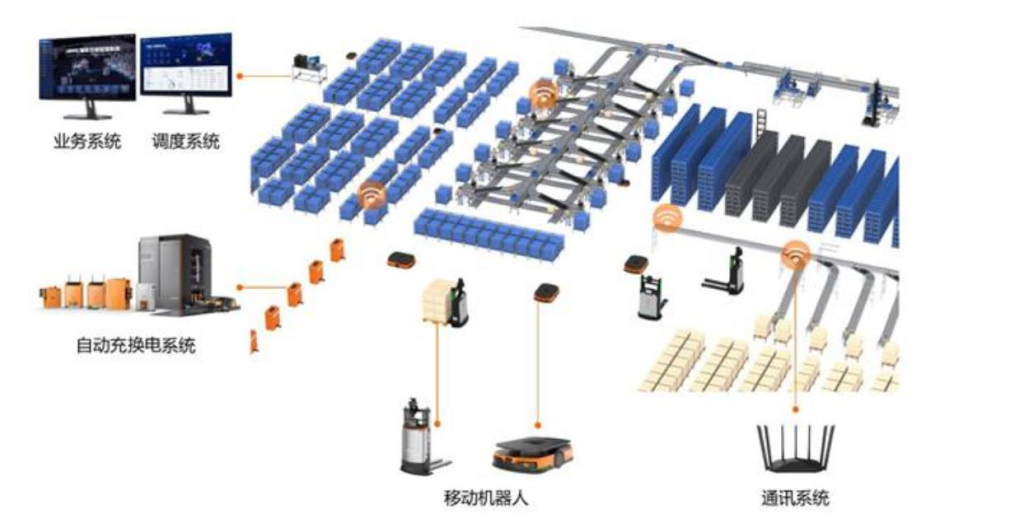
机器视觉赋能,打造长期壁垒。区别于传统的自动导航车辆(AGV)依赖于预设的路线和人工监督,AMR 需要利用机器视觉技术进行实时的导航和路径规划,以实现自主移动。因此 AMR 对于机器视觉的要求大大提高。根据 Omdia 报告,海康机器人公司的母公司海康威视连续 8 年蝉联视频监控行业全球第一,占全球视频监控市场份额的 24.1%。公司在机器视觉方面具备深厚技术积累,拥有2D 视觉、智能 ID、3D 视觉三大硬件产品线。其中 2D 系列产品中的工业相机作为公司最早布局的核心成像产品,在市场占有率及产品性能方面均居于业内领先地位。